Region-Based Spatiotemporal Attention
|
|
|
|
Summary
Artificial visual attention can filter image data to reduce data for higher level processing. For example, if you (as a human) wanted to drink from a cup, you probably needed several information to perform this action. To localize the cup in a complex scene and guide the action towards it, you would not part by part analyze the scene from top-left to bottom-right or in any other naive manner. You could directly approach the cup as your attention system has filtered out everything that is not important for this task. Also, you might be able to grab and drink from the cup without any consciousness of the cup's position or orientation.Technical systems can benefit from such attentional mechanisms as well. We usually consider two streams in attentional systems. One is bottom-up saliency, which is data driven depending on contrasts, like bright among dark, dark among bright, tilted among straight, straight among tilted or contrasts of other low-level features. The other stream is top-down, knowledge driven and reflects task relevance. This enhances the saliency of objects relevant for the current tasks. From both streams combined, a 'Focus of Attention' can be retrieved, which marks the spot in the scene that should be attended now.
Features like brightness and orientations are of static nature, but it is known that dynamic features like motions are very strong in attracting attention. Also moving objects are relevant for a lot of tasks. Hence, the focus of the projects introduced here is to integrate saliency calculations for dynamic features. The work we do in this domain is based on region-based processing of spatiotemporal slices that are not 2-dimensional images in normal spatial dimension x and y, but 2-dimensional x - t and y - t images.
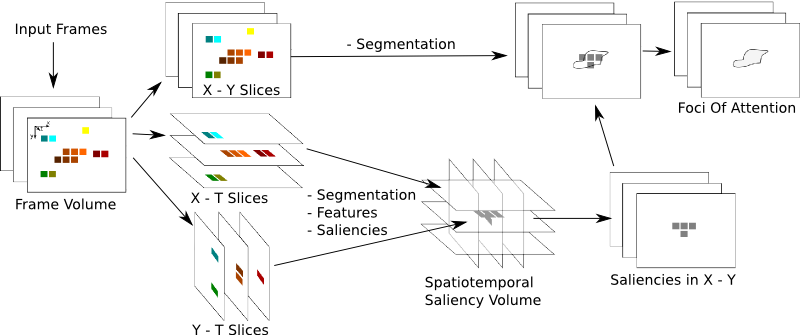
Fig. 1: The chart depicts a spatiotemporal attention model, which uses spatial methods on x - y, x - t and y - t slices. As an intitial step a volume of frames is collected and divided into stacks of the three cutting direction. Saliencies are computed for each stack in a region based way. Then the resulting saliency volumes are blended together and sliced back to normal oriented x - y slices, from which the activation is collected back into regions of the spatial segmentation. The maximum of these is the focus of attention.
Plug-in components (left center) allow individual modules that can be integrated at run-time as needed. The communication between applications and the simulator (bottom left) is primarily implemented through the middleware (bottom right) such as the Robot Operating System.
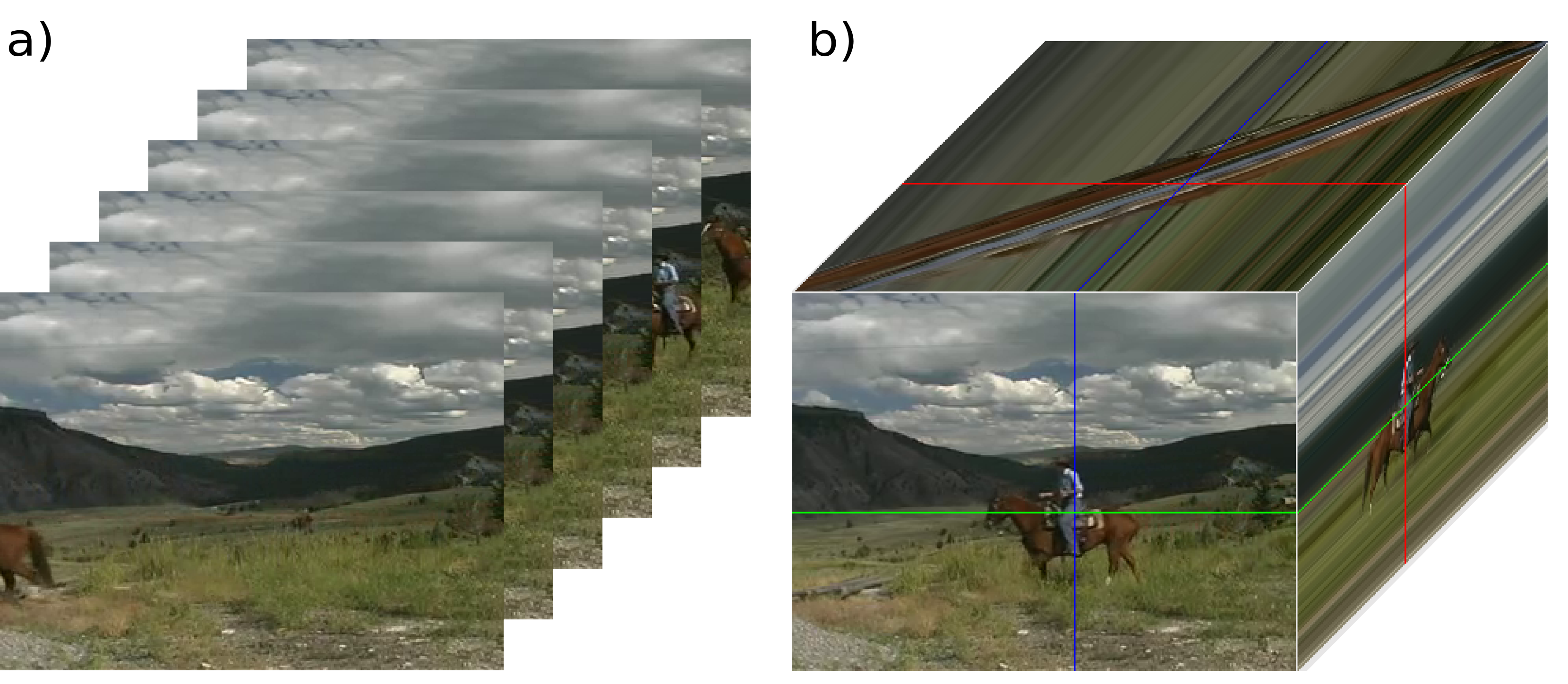
Fig 2: When consecutive frames (a) are gathered to form a spatiotemporal frame volume (b) saliently moving objects pop out from their environment. The images on the faces of the cube visualization (b) show slices from the inside of the volume. The colored marker frames indicate the slices' origins inside the volume. In the x - t images (top-face) the horse produces a motion signature that is tilted compared to the background regions. The orientation, which corresponds to the motion will render the object salient in spatiotemporal saliency processing.