Artificial Visual Attention using Pre-attentional Structures
|
|
|

|
Summary
Selective visual attention is a concept from the psychology of perception in humans that summarizes processes that deal with filtering relevant from irrelevant visual information. A popular consequence of selective attention is for example the gorilla that wals through a scene unnoticed when observers have the task of counting passes with a basketball. You may have seen this video. And yes, it originates from a scientific study [Simons & Chabris, 1999]. It may seem like a human deficit to miss such an unusual character in a visual scene. However, it shows how the human perception is guided towards what it important in a scene for a given task. Flexibiliy without any effort we can attend to important things and event in everyday scenarios, more challenging ones such as driving a car, and even in highly artificial situations such as whatching cartoons, playing computer games, or reading this website.
This ability to flexibly selecting just the right visual information is highly attractive for researchers in the field of artificial cognitive systems, such as robots, surveillance systems or driver assistance systems. And therefore, a variety of technical attention models has been developed in the past thirty years and artificial attention constitutes a highly active field of research ever since.
In GET Lab we are working on a particular type of visual attention model with the ultimate goal of providing flexible attentional mechanisms for autonomous robots. In this type of model, pre-attentional structures are obtained first. These are elements that compete for the focus of attention. The competition is guided by a variety of influences, such as conspicuities in the data, targets for specific tasks, or action possibilities of the system. Finally, everything is integrated in to an overall attention map that can be used to guide attention for a visual scene. The different stages of this procedure are outlined in the following.
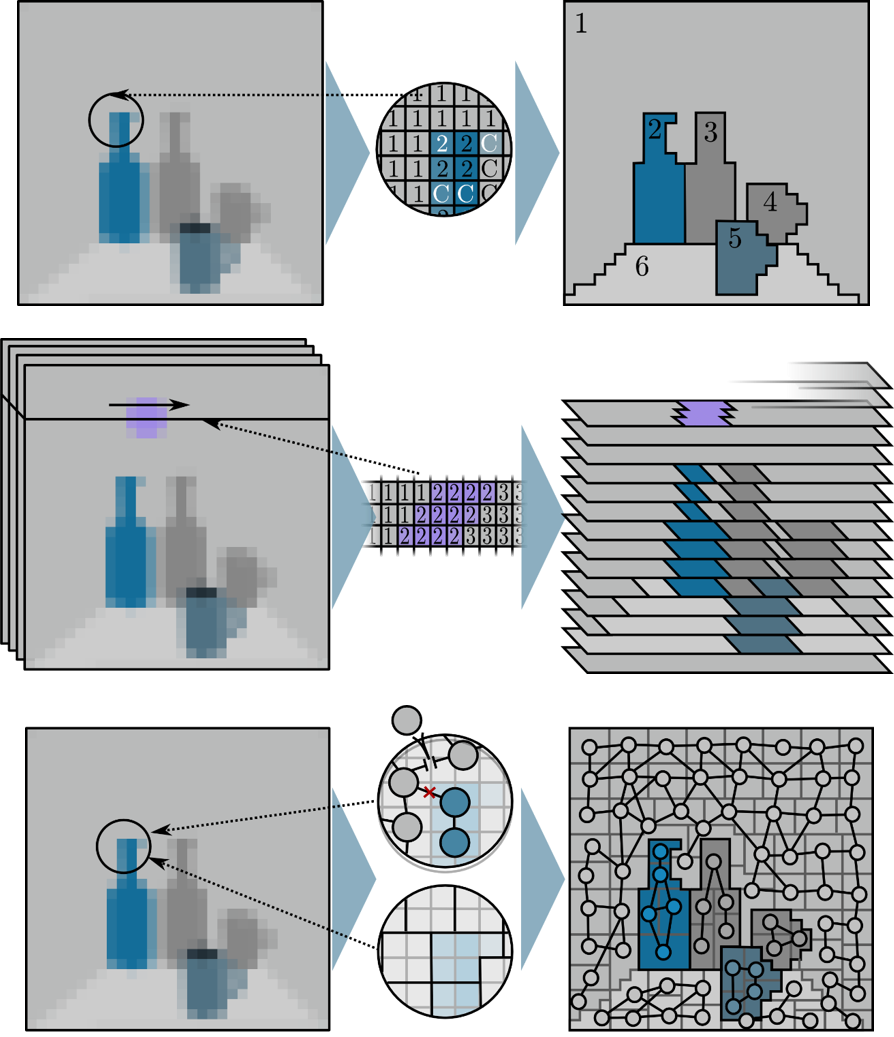
Extracting pre-attentional structures
In the first stage, pre-attentional structures are extracted. "Pre-attentional" means that the extraction is performed without considering any importance yet for the whole image. These structures constitute the basic units which are used for the attention calculations in the subsequent processes. Note that in the examples in the figures the pre-attentional structures represent complete objects. In real images, this is typically not the case and objects are split up into several pre-attentional structures.Different methods can be employed to extract pre-attenional structures (see Fig 1). The only requirement is that for theses structures local attributes, such as average color, orientation, size, symmetry, eccentricity or others can be calculated. In the past, we worked with color-based image segmentation in the spatial and spatiotemporal domain on the CPU and GPU. More recently, graph-based structures obtained with the Growing Neural Gas approach have been used.
The following references contain technical details about theses methods:
Z. Aziz and B. Mertsching. Color Segmentation for a Region-Based Attention Model. In: 12. Workshop Farbbildverarbeitung 2006, Ilmenau, Germany, 2006, pp. 74-83. ISSN 1432-3346M. Backer, J. Tünnermann, and B. Mertsching. Parallel k-Means Image Segmentation Using Sort, Scan & Connected Components on a GPU. 2013. ISBN 978-3-642-35892-0
J. Tünnermann and B. Mertsching. Continuous Region-Based Processing of Spatiotemporal Saliency. In: International Conference on Computer Vision Theory and Applications, 2012, pp. 230-239.
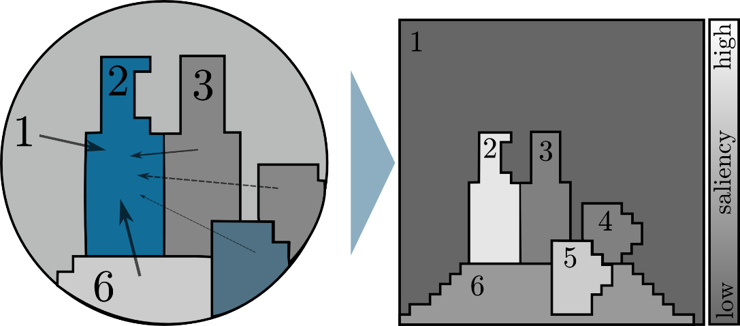
Calculating bottom-up saliency
In the bottom-up saliency calculation, pre-attentional structures distribute vote for how different they are from each other (see Fig. 2).Z. Aziz and B. Mertsching. Fast and Robust Generation of Feature Maps for Region-Based Visual Attention. In: IEEE Transactions on Image Processing, 2008, vol. 17, May 2008, no. 5, pp. 633-644. ISSN 1057-7149
J. Tünnermann and B. Mertsching. Region-Based Artificial Visual Attention in Space and Time. In: Cognitive Computation, 2014, vol. 6, no. 1, pp. 125-143. ISSN 1866-9964
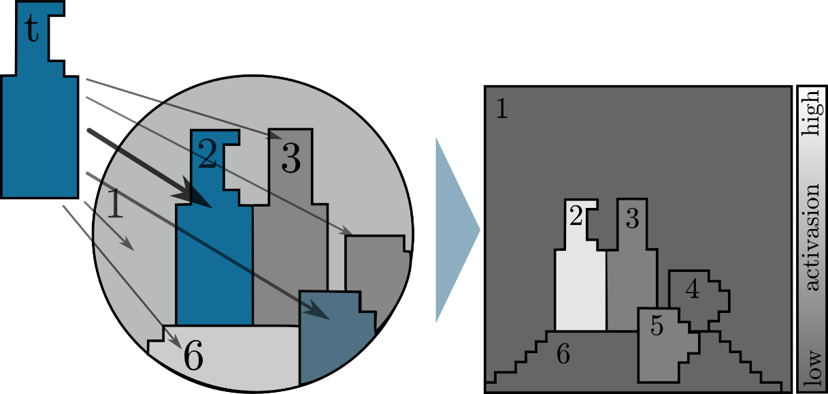
Top-down influences
A simple top-down influence is assigning activation based on similarity to a template. Typically this is done for multiple feature dimensions (color, orientation, symmetry, etc.). Interesting topics for future research managing memory structures that contain such template representations which are dynamically added and retrieved on demand.Z. Aziz and B. Mertsching. Region-Based Top-Down Visual Attention Through Fine Grain Color Map. In: Workshop Farbbildverarbeitung (FWS 2007), 2007, pp. 83-92.
C. Born. Adaptive Top-Down Vorlagen zur Steuerung Künstlicher Aufmerksamkeit. Bachelor's thesis, Paderborn University, 2012.
J. Tünnermann, C. Born, and B. Mertsching. Top-Down Visual Attention with Complex Templates. In: International Conference on Computer Vision Theory and Applications, 2013, pp. 370-377.
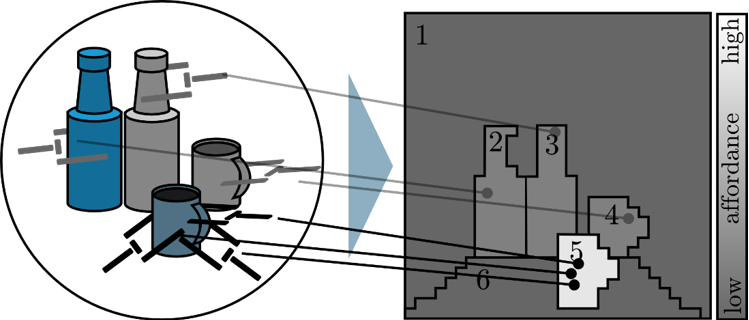
Object affordances
Object affordances are action possibilites objects offer. For example, a door may afford grasping via its handle. When these can be approximated quickly in early vision, they can be used to guide attention toward action-relevant objects in the scene.J. Tünnermann, C. Born, and B. Mertsching. Integrating Object Affordances with Artificial Visual Attention. In: Computer Vision - ECCV 2014 Workshops - Zurich, Switzerland, September 6-7 and 12, 2014, Proceedings, Part II, 2015, pp. 427-437.
J. Tünnermann, N. Krüger, B. Mertsching, and W. Mustafa. Affordance Estimation Enhances Artificial Visual Attention: Evidence from a Change Blindness Study. In: Cognitive Computation, 2015, vol. 7, no. 5, pp. 526-538.