Summary |
Learning a representation of an environment is of significant importance for the autonomous navigation of vehicles. In
this respect, the mechanical systems, e.g., a mobile robot or a vehicle, are typically equipped with the motion sensors and
their position is tracked. These sensors are prone to errors due to hardware wear out or randomness in an environment
(e.g. slippery or uneven terrains). To minimize the errors in position estimates, auxiliary sensors, such as optical camera
or laser range finders, are employed. Such a process of estimating the robot's position and at the same time building the
spatial representation of an environment (a Cartesian map) is termed as Simultaneous Localization and Mapping (SLAM) or Robotic Mapping.
Biological systems, including humans, have a remarkable ability to navigate through diverse environments. For this purpose,
they principally rely on visual cues and acquire a topological layout of an environment instead of learning accurate geometric
maps [1]. Hence, our interpretation of an environment in the brain is topological rather than being
strictly metric. Ample research has been dedicated in recent years to develop the technical systems that use place recognition
and/or topological relationship among places to perform mapping, e.g., appearance-based mapping [2].
A mainstream of existing work in appearance-based mapping is either based on offline learning or requires environment-specific
parameter tuning. In consequence, these approaches cannot be extended readily to perform mapping in unknown environments. The
goal of this research is to address the challenges of real-time scene learning and recognition for robotic mapping; whereas
the biological aspect is to exploit the strengths of the human vision and learning system (i.e. certain areas of visual cortex
and hippocampus) so that the natural responses to images can be extracted and learned incrementally.
|
Current Research |
The focus of this research is to extend and develop technical systems that emulate the learning, recognition and
navigation mechanisms in biological neurons [3]. To leverage the efficiency and adaptability in
technical systems, optimization techniques are also under study.
|
| Extract Human-like Scene Representations |
Exploit the strengths of the human vision system to obtain the natural responses to images. In this regard,
the following approaches can be considered:
- Gist of the Scene: Humans interpret the meaning of a scene within ~200 ms of its presentation to the retina, provided
the eye fixations or exposures to a new scene are separated by a gap of a few milliseconds. This initial scene representation has
been called as the "gist of a scene" [5].

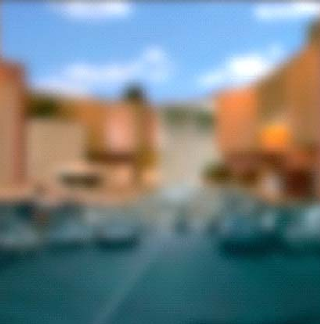 Observe the images from left-to-right: Looking at the left image gives an interpretation of the scene as a roadway with buildings
alongside and cars on the road. Note that the top part in the blurred image, which gives an impression of buildings, is instead
blended with cabinets from a kitchen (see the image on right side). False interpretations of the scene do not suggest the failure
of a human vision system. This observation rather strengthens the fact that the perceptual formation of a scene is described by
the global context.
The structural layout of a scene can be characterized by global attributes (e.g. degree of naturalness, openness,
etc.) and thus avoid the overhead of fine-grained image analysis [4].
Observe the images from left-to-right: Looking at the left image gives an interpretation of the scene as a roadway with buildings
alongside and cars on the road. Note that the top part in the blurred image, which gives an impression of buildings, is instead
blended with cabinets from a kitchen (see the image on right side). False interpretations of the scene do not suggest the failure
of a human vision system. This observation rather strengthens the fact that the perceptual formation of a scene is described by
the global context.
The structural layout of a scene can be characterized by global attributes (e.g. degree of naturalness, openness,
etc.) and thus avoid the overhead of fine-grained image analysis [4].

To obtain the gist features, the energy spectrum of an image is sampled using a set of Gaussian functions at different scales and orientations.
Degree of expansion: horizontally dominant (a) power spectrum. Degree of naturalness: vertically dominant (c) or isotropic (e) power spectrum.
Degree of openness: oblique shape (d) power spectrum represent the scenes with several boundary elements, and thus indicate lesser degree of openness.
- Convolution neural networks (ConvNet): The training of ConvNets is used to obtain representations that are robust to
illumination, appearance and viewpoint changes [6].
|
| Learning Representations of Places |
The formation of spatial memory in brain is governed by cells that show competitive
behavior to learn the input, while inhibiting the activity of topologically farther neurons. To model a similar behavior,
a modified version of growing self-organizing map (GSOM) has been proposed [7]. Such a system
offers a robust solution to place recognition (i.e. loop-closure detection).

This model is further extended to fuse the nearby context for learning a robust visual representation of the environment (cf. [8]).
|
| Search Optimization |
| The growing size of the learned representation imposes demands for fast searching algorithms. In this respect, several search optimization
methods are in consideration, e.g., locality sensitive hashing, tree structures, approximate nearest neighbor, etc. Moreover, the research also focuses on stochastic methods
for learning optimal parameters settings, such as Bayesian optimization, etc.
|
Selected References |
| 1. |
Milford, M., & Wyeth, G. (2008). Mapping a Suburb with a Single Camera Using a Biologically Inspired SLAM System. In: IEEE Transactions on Robotics. |
| 2. |
Cummins, M., and Newman, P. (2011). Appearance-only SLAM at Large Scale with FAB-MAP 2.0. In: International Journal of Robotics Research (IJRR). |
| 3. |
Kazmi, S. M. A. M., and Mertsching, B. (2016a). Gist+RatSLAM: An Incremental Bio-inspired Place Recognition Front-end for RatSLAM. In: 9th International
Conference on Bio-inspired Information and Communications Technologies (BICT). |
| 4. |
Oliva, A., and Torralba, A. (2001). Modeling the Shape of the Scene: A Holistic Representation of the Spatial Envelope. International Journal of Computer
Vision (IJCV). |
| 5. |
Oliva, A. (2005). Gist of the Scene. In: Neurobiology of Attention. |
| 6. |
Zhou, B., et al. (2017). Places: A 10 Million Image Database for Scene Recognition. In: IEEE Transaction on Pattern Analysis and Machine Intelligence. |
| 7. |
Kazmi, S. M. A. M., and Mertsching, B. (2016b). Simultaneous Place Learning and Recognition for Real-time Appearance-based Mapping. In: IEEE/RSJ International
Conference on Intelligent Robots and Systems (IROS). |
| 8. |
Kazmi, S. M. A. M., and Mertsching, B. (2019). Detecting the Expectancy of a Place Using Nearby Context for Appearance-based Mapping. In: IEEE Transactions on Robotics (T-RO). |
|
Contact |
| For further queries (or comments), please contact: |
|
|

